


1 Partie C de l'examen
La commande ecrivain
La syntaxe de la commande ecrivain est la suivante :
ecrivain
[-p psize]
[-s size]
[inputfile
[outputfile]]
Elle génère dans le fichier outputfile (par défaut
la sortie standard) un fichier d'au plus size mots
(par défaut 1000), à partir du fichier inputfile
(par défaut l'entrée standard). L'algorithme utilise des préfixes de
psize mots (2 par défaut).
Une structure de données pour la commande ecrivain
Pour que l'algorithme de génération de texte fonctionne correctement,
le volume de l'entrée doit être relativement important, par exemple le
contenu complet d'un livre [On s'apprête donc à traiter
de l'ordre de 100.000 mots en entrée et de l'ordre de 1.000 mots en
sortie. La commande ne peut reposer sur une structure de données
simpliste (par exemple la liste des mots) sous peine de performances
détestables : 1000 fois une recherche séquentielle dans une liste de
100.000 mots.].
Nous allons construire une structure de données qui associe un préfixe
et l'ensemble de ses suffixes. Lors de la première phase de
l'algorithme (construction de la structure de données à partir du
texte d'entrée), il est nécessaire de retrouver la structure d'un
préfixe donné pour y ajouter un nouveau suffixe. Lors de la seconde
phase de l'algorithme (génération du texte), il est nécessaire de
retrouver la structure d'un préfixe donné pour choisir aléatoirement
un de ses suffixes. Dans les deux cas, l'algorithme demande de
retrouver rapidement l'ensemble des suffixes d'un préfixe donné. Nous
pouvons utiliser une table de hachage.
Le principe d'une table de hachage est de partitionner l'ensemble des
éléments en un nombre N, fixé, de listes. Une table de hachage est
ainsi vue comme un tableau de N listes d'éléments. Une fonction (la
fonction de hachage) retourne pour un élément donné un entier qui est
un indice dans ce tableau. Ainsi, la recherche de la position d'un
élément dans la table de hachage [que ce soit pour
accéder à l'élément ou l'insérer dans la table] commence par
calculer cet indice ; avec cet indice, on accède dans la table de
hachage à une liste d'éléments ; on recherche alors séquentiellement
dans la liste correspondante l'emplacement de l'élément. L'efficacité
d'une table de hachage réside dans le choix judicieux de la fonction
de hachage ; son exécution doit être peu coûteuse et les indices
produits par cette fonction sur l'ensemble des éléments doivent bien
se répartir entre 0 et N-1.
La structure de données associée à un préfixe est la suivante :
unsigned int PLEN ; /* longueur des préfixes (nombre de mots dans un préfixe) */
typedef struct prefix Prefix ;
typedef struct suffix Suffix ;
struct prefix {
char **words ; /* le tableau (de taille PLEN) des mots du préfixe */
Suffix *suffixes ; /* la liste des suffixes */
} ;
struct suffix {
char *word ; /* la valeur du suffixe */
Suffix *nextS ; /* le suivant dans la liste des suffixes du préfixe */
} ;
La table de hachage est alors déclarée ainsi :
#define NHASH 4093 /* taille du tableau constituant la table de hachage */
/* Un élément d'une liste de la table de hachage */
typedef struct elem Elem ;
struct elem {
Prefix prefix ; /* le prefixe */
Elem *nextE ; /* l'élément suivant dans la liste */
} ;
/* La table de hachage */
Elem *hashtable [NHASH] ;
La figure 1 illustre cette structure de données.
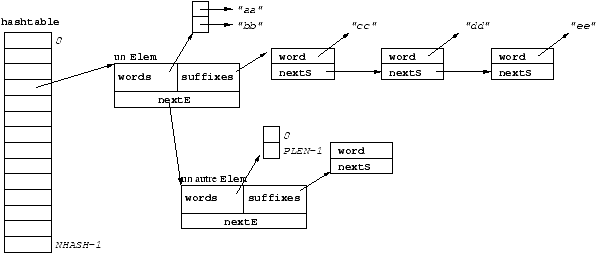
Figure 1 : Une table de hachage pour ecrivain
(PLEN vaut 2)
On utilise la fonction de hashage suivante :
/* la fonction de hashage. Retourne un entier inférieur à NHASH à
partir d'un tableau de PLEN mots constituant un préfixe. */
unsigned int hash (char *words[]) ;
Questions -- Partie C
Question 1
La table de hachage est organisée sous forme de listes de préfixes
lesquels sont mémorisés sous forme de tableaux de PLEN
mots. Nous avons besoin d'une fonction de test d'égalité de deux
préfixes :
int prefixeql (const char *words1[], const char *words2[]) ;
retourne zéro si et seulement si les deux préfixes sont
différents.
Donnez le code C de la fonction prefixeql ().
Question 2
La fonction addsuffix () ajoute un suffixe donné à la
liste des suffixes d'un préfixe donné :
void addsuffix (Prefix *p, const char *suffix) ;
Il est garanti que la chaîne de caractères suffix sera
inchangée dans la suite du programme (elle n'a donc pas à être
recopiée).
On ne se préoccupe pas de savoir si le suffixe est déja présent
dans la liste des suffixes [Plus un suffixe apparaît
dans le texte original, plus il doit avoir de chance
d'apparaître dans le texte généré. Nous ne gérons pas un
compteur associé à chacun des suffixes mais procédons par
présence multiple du suffixe dans la liste des suffixes.].
Donner le code C de la fonction addsuffix ().
Question 3
La fonction lookup () recherche un préfixe (tableau
words de PLEN chaînes de caractères) donné dans
la table de hachage. Elle retourne un pointeur sur le préfixe.
Prefix *lookup (const char *words[], unsigned int create) ;
Le paramètre create indique le comportement de
lookup () dans le cas où le préfixe n'est pas présent :
-
si create est nul, lookup () retourne
NULL ;
- sinon, lookup () ajoute le préfixe à la table de
hachage hashtable.
Dans ce cas, il est garanti que les chaînes de caractères de
words seront inchangées dans la suite du programme.
Inversement, le tableau words doit être dupliqué.
Donner le code C de la fonction lookup ().
Question 4
La fonction getasuffix () retourne un suffixe choisi
aléatoirement parmi les suffixes du préfixe donné par le tableau
de PLEN chaînes de caractères :
char *getasuffix (char *words[]) ;
Il est garanti qu'un tel suffixe existe dans la table de
hachage [On sort du programme sur une erreur fatale
(un bug de notre programme !) sinon. En effet pour tout préfixe
du texte initial, il y a un suffixe dans la table de hachage.
Seul le dernier préfixe du texte pourrait ne pas être présent
dans la table. On a donc ajouté, en fin de création de la table,
le suffixe "" associé à ce dernier préfixe.].